In a world awash with the rapid tide of generative AI technologies, governments are waking up to the need for a guiding hand. President Biden’s Executive Order is an exemplar of the call to action, not just within the halls of government but also for the sprawling campuses of tech enterprises. It’s a call to gather the thinkers and doers and set a course that navigates through the potential perils and benefits these technologies wield. This is more than just a precaution; it’s a preemptive measure. Yet these legislative forays are more like sketches than blueprints, in a landscape that’s shifting, and the reticence of legislators is understandable and considered. After all, they’re charting a world where the very essence of our existence — our life, our freedom, our joy — could be reshaped by the tools we create.
On a brisk autumn day, the quiet serenity of Maine became the backdrop for a gathering: The RAISE Symposium, held on October 30th, which drew some 60 souls from across five continents. Their mission? To venture beyond the national conversations and the burgeoning frameworks of regulation that are just beginning to take shape. We convened to ponder the questions of generative AI — not in the abstract, but as they apply to the intimate dance between patient and physician. The participants aimed to cast a light on the issues that need to be part of the global dialogue, the ones that matter when care is given and received. We did not an attempt to map the entirety of this complex terrain, but to mark the trails that seemed most urgent.
The RAISE Symposium’s attendees raised (sorry) a handful of issues and some potential next steps that appeared today in the pages of NEJM AI and Nature Medicine. Here I’ll focus on a singular quandary that seems to hover in the consultation rooms of the future: For whom does the AI’s medical counsel truly toll? We walk into a doctor’s office with a trust, almost sacred, that the guidance we receive is crafted for our benefit — the patient, not the myriad of other players in the healthcare drama. It’s a trust born from a deeply-rooted social contract on healthcare’s purpose. Yet, when this trust is breached, disillusionment follows. Now, as we stand on the precipice of an era where language models offer health advice, we must ask: Who stands to gain from the advice? Is it the patient, or is it the orchestra of interests behind the AI — the marketers, the designers, the stakeholders whose fingers might so subtly weigh on the scale? The symposium buzzed with talk of aligning AI, but the compass point of its benefit — who does it truly point to? How do we ensure that the needle stays true to the north of patient welfare? Read the article for some suggestions from RAISE participants.
As the RAISE Symposium’s discussions wove through the thicket of medical ethics in the age of AI, other questions were explored. What is the role of AI agents in the patient-clinician relationship—do they join the privileged circle of doctor and patient as new, independent arbiters? Who oversees the guardianship of patient data, the lifeblood of these models: Who decides which fragments of a patient’s narrative feed the data-hungry algorithms?
The debate ventured into the autonomy of patients wielding AI tools, probing whether these digital oracles could be entrusted to patients without the watchful eye of a human professional. And finally, we contemplated the economics of AI in healthcare: Who writes the checks that sustain the beating heart of these models, and how might the flow of capital sculpt the very anatomy of care? The paths chosen now may well define the contours of healthcare’s landscape for generations to come.
After you have read the jointly written article, I and the other RAISE attendees hope that it will spark discourse between you and your colleagues. There is an urgency in this call to dialogue. If we linger in complacency, if we cede the floor to those with the most to gain at the expense of the patient, we risk finding ourselves in a future where the rules are set, the die is cast, and the patient’s voice is but an echo in a chamber already sealed. It is a future we can—and must—shape with our voices now, before the silence falls.
I could have kicked off this blog post with a pivotal query: Should we open the doors to AI in the realm of healthcare decisions, both for practitioners and the people they serve? However considering “no” as an answer seemed disingenuous. Why should we not then question the very foundations of our digital queries—why, after all, do we permit the likes of Google and Bing to guide us through the medical maze? Today’s search engines, with their less sophisticated algorithms, sit squarely under the sway of ad revenues, often blind to the user’s literacy. Yet, they remain unchallenged gateways to medical insights that sway critical health choices. Given that outright denial of search engines’ role in health decision-making seems off the table and acknowledging that generative AI is already a tool in the medical kit for both doctors and their patients, the original question shifts from a hypothetical to a pragmatic sphere. The RAISE Symposium stands not alone but as one voice among many, calling for open discussions on how generative AI can be safely and effectively incorporated into healthcare.
Version 0.6 (Revision history at the bottom) November, 30, 2023
Much has been written about harmonizing AI with our ethical standards, a topic of great significance that still demands further exploration. Yet, an even more urgent matter looms: realigning our healthcare systems to better serve patients and society as a whole. We must confront a hard truth: the alignment of these systems with our needs has always been imperfect, and the situation is deteriorating.
My purpose is not to sway healthcare policy but to shed light on this issue for a specific audience: my peers in computer science, along with students in both medicine and computer science. They frequently pose questions to me, prompting this examination. These inquiries aren’t just academic or mercantile; they reflect a deep concern about how our healthcare systems are failing to meet their most fundamental objectives and an intense desire to bring their own expertise, energy and optimism to address these failures.
A sampling of these questions
Which applications to clinical medicine are ripe for improvement or disruption by the application of AI?
What do I have to demonstrate to get my AI program adopted?
Who decides which programs are approved or paid for?
This program we’ve developed helps patients. So why are doctors, nurses and other healthcare personnel so reluctant to use our program?
Why can’t I just market this program directly to patients?
To avoid immediately disappointing any reader, beware, I am not going to answer those questions here although I have done so in the past and will continue to do so. Here I will focus only on the misalignment between organized/establishment healthcare and its mission to improve the health of members of our society. Understanding the misalignment is a necessary preamble to answering the questions of the sort listed above.
Basic Facts of Misalignment of Healthcare
Let’s proceed to some of the basic facts about the healthcare system and the growing misalignments. Again, many of these pertain to several developed countries but they are most applicable to the US.
Primary care is the where you go for preventive care (e.g. yearly checkups) and go first when you have a medical problem. In the US, primary care doctors are amongst the lowest paid. They also have a constantly increasing administrative burden. As a result, despite the growing needs for primary care with the graying of our citizens, the gap between the number of primacy care doctors and the need for such doctors may exceed 40,000 within the next 10 years in the US alone.
Projected shortage in primary care physicians (AAMC study)
In response to the growing gap between the demand for primary care and the availability of primary care doctors, the U.S. healthcare system has seen a notable increase in the employment of nurse practitioners (NPs) and physician assistants (PAs). These professionals now constitute an estimated 25% of the primary care workforce in the United States, a figure that is expected to rise in the coming years.
You might think that the fact that U.S. doctors earn roughly double the income of doctors in Europe would result in a stable workload. Despite this higher pay, they face relentless pressure, often exerted by department heads or hospital administrators, to see more patients each day.
The thorough processes that were once the hallmark of medical training—careful patient history taking, physical examinations, crafting thoughtful diagnostic or management plans, and consulting with colleagues—are now often condensed into forms that barely resemble their original intent. This transformation of medical practice into a high-pressure, high-volume environment contributes to several profound issues: clinician burnout, patient dissatisfaction, and an increased likelihood of clinical errors. These issues highlight a growing disconnect between the healthcare system’s operational demands and the foundational principles of medical practice. This misalignment not only affects healthcare professionals but also has significant implications for patient care and safety.
The acute workforce shortage in healthcare extends well beyond the realm of primary care, touching various subspecialties that are often less lucrative and, perhaps as a result, perceived as less prestigious. Fields such as Developmental Medicine, where children are assessed for conditions like ADHD and autism, pediatric infectious disease, pediatric endocrinology, and geriatrics, consistently face the challenge of unfilled positions year after year.
This shortage is compounded by a growing trend among medical professionals seeking careers outside of clinical practice. Recent surveys indicate that about one-quarter of U.S. doctors are exploring non-clinical career paths in areas such as industry, writing, or education. Similarly, in the UK, half of the junior doctors are considering alternatives to clinical work. This shift away from patient-facing roles points to deeper issues within the healthcare system, including job dissatisfaction, the allure of less stressful or more financially rewarding careers, and perhaps a disillusionment with the current state of medical practice. This trend not only reflects the personal choices of healthcare professionals but also underscores a systemic issue that could further exacerbate the existing shortages in crucial medical specialties, ultimately impacting patient care and the overall effectiveness of the healthcare system.
Doctors have been burned by information technology: Electronic health records (EHRs). Initially introduced as a tool to enhance healthcare delivery, EHRs have increasingly been utilized primarily for documenting care for reimbursement purposes. This shift in focus has led to a significant disconnect between the potential of these systems and their actual use in clinical settings. Most of the currently widely used implementations over the last 15 years have rococo user interfaces that would offend the sensibilities of most “less is more” advocates. Many technologists will be unaware of the details of clinicians’ experience with these systems because EHR companies will have contractually imposed gag orders to prevent doctors from publishing screenshots. Yet these same EHR systems are widely understood to be major contributors to doctor burnout and general disaffection with clinical care. These same EHR’s cost millions (hundreds of millions for a large hospital) and have made many overtaxed hospital information technology leaders wary of adopting new technologies.
At least 25% of the US healthcare costs are administrative. This administrative overhead heaped atop of the provisioning of healthcare services includes the tug of war between healthcare providers and healthcare payors on how much to bill and how much to reimburse. It also includes the authorization for procedures, referrals, the multiple emails and calls to coordinate care between the members of the care team writ large (pharmacist, visiting nurse, rehabilitation hospital, social worker) and the multiple pieces of documentation entailed by each patient encounter (e.g. post-visit note to the patient, to the billing department, to a referring doctor). These non-clinical tasks don’t have the same liability as patient care and the infrastructure to execute them is more mature. As noted by David Cutler and colleagues, this makes it very likely that administrative processes will present the greatest initial opportunity for a broad foothold of AI into the processes of healthcare.
Even in centralized, nationalized healthcare systems there is a natural pressure to do something when faced with a patient who is suffering or worried. Watchful waiting, when medically prudent, requires ensuring that the patient understands that not doing anything might be the best course of action. This requires the doctor to establish trust during the first visit and in future visits, so the patient can be confident that their doctor will be vigilant and ready to change course when needed. This requires a lot more time and communication than many simple treatments or procedures. The pressure to treat is even more acute when reimbursement for healthcare is under a fee-for-service system, as is the case for at least 1/3 of US healthcare. That is, doctors get paid for delivering treatments rather than better outcome. One implication is that advice (by humans or AI) to not deliver a treatment might be in financial conflict with the interests of the clinician.
The substrate for medical decision-making is high-quality data about the patients in our care. Those data are often obtained at considerable effort, cost and risk to the patient (e.g, when involving a diagnostic procedure). Sharing those data across healthcare wherever it is provided has been an obvious and long-sought goal. Yet in many countries, patient data remains locked in propriety systems or accessible to only a few designees. Systematic and continual movement of patient data to follow them across countries is relatively rare and incomplete. EHR companies that have large marketshare therefore have outsized leverage in influencing the process of healthcare, of guiding medical leaders to market patient data (e.g for market research or training AI models). They are often also aligned with healthcare systems that would rather not share clinical data with their competitors. Fortunately, the 21st Century Cures act passed by the US congress has explicitly provided for the support of APIs such as SMART-on-FHIR to allow patients to transport their data to other systems. The infrastructure to support this transport is still in its infancy but has been accelerated by companies such as Apple which have provided customers access to their own healthcare records across hundreds of hospitals.
Finally, at the time of this writing (2023) hospitals and healthcare systems are under enormous pressure to deliver care in a more timely and safer fashion and simultaneously are financially fragile. This double jeopardy was accentuated by the consequences of the 2020 pandemic. It may also be that the pandemic merely accelerated the ongoing misalignment between medical capabilities, professional rewards, societal healthcare needs and an increasingly anachronistic and inefficient medical education and training process. The stresses caused by the misalignment may create cracks into which new models of healthcare may find a growing niche but it might also bolster powerful reactionary forces to preserve the status quo.
Did I miss an important gap relevant to AI/CS scientists, developers or entrepreneurs? Let me know by posting in this post’s comments section (which I moderate) or just reply to my X/Twitter post @zakkohane.
Version
Comment
0.1
Initially covered many more woes of medicine
0.2
Refocused on bits most relevant to AI developers/computer scientists.
0.3
Removed many details that detracted from the message
0.4
Inserted the kinds of questions that I have answered in the past but need to first provide this bulletized version of the misalignments of the healthcare system as a necessary preamble.
0.5
Added more content on EHR’s and corrected cut and paste errors! (Sorry!)
0.6
Added positions unfilled as per https://twitter.com/jbcarmody/status/1729933555810132429/photo/1
In population genetics, it’s canon that selecting for a trait other than fitness will increase the likelihood of disease, or at least characteristics that would decrease survival in the “wild”. This is evident in agriculture, where delicious fat corn kernels are embedded in husks so that human assistance is required for reproduction or where breast-heavy chickens have been bred that can barely walk . I’ve been wondering about the nature of the analogous tradeoff in AI. In my experience with large language models (LLM)—specifically GPT-4—in the last 8 months, the behavior of the LLM has changed over the short interval of my experience. Compared to logged prompt/responses I have from November 2022 (some of which appear in a book) the LLM is less argumentative, more obsequious but also less insightful and less creative. This publication now provides plausible, quantified evidence that there has indeed been a loss of performance in only a few months in GPT-3.5 and GPT-4. This in tasks ranging from mathematical reasoning to sociopolitically enmeshed assessments.
This study by Zou and colleagues at Berkeley and Stanford merits its own post for all its implications for how we assess, regulate, and monitor AI applications. But here, I want to briefly pose just one question that I suspect will be at the center of a hyper-fertile domain for AI research in the coming few years: Why did the performance of these LLMs change so much? There may be some relatively pedestrian reasons: The pre-trained models were simplified/downscaled to reduce response time and electricity consumption or other corner-cutting optimizations. Even if that is the case, at the same time, we know because they’ve said so (see quote below), that they’ve continued to “steer” (“alignment” seems to be falling into disfavor) the models using a variety of techniques and they are getting considerable leverage from doing so.
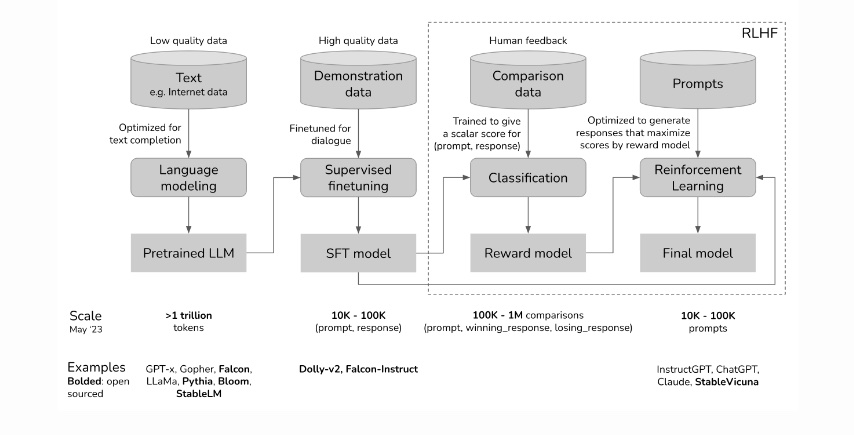
Much of this steering is driven by human-sourced generation and rating of prompts/responses to generate a model that is then interposed between human users and the pre-trained model (see this post by Chip Huyen from which I copied the first figure above which outlines how RLHF—Reinforcement Learning from Human Feedback—is implemented to steer LLMs). Without this steering, GPT would often generate syntactically correct sentences that would be of little interest to human beings. So job #1 of RLHF has been to generate human relevant discourse. The success of ChatGPT suggests that RLHF was narrowly effective in that sense. Early unexpected antisocial behavior of GPT gave further impetus to additional steering imposed through RLHF and other mechanisms.
The connections between the pre-trained model and the RLHF models are extensive. It is therefore possible that modifying the output of the LLM through RLHF can have consequences beyond the narrow set of cases considered during the ongoing steering phase of development. That possibility raises exciting research questions, a few of which I have listed below.
Question
Elaboration and downstream experiments
Does RLHF degrade LLM performance?
What kind of RLHF under what conditions? When does it improve performance?
How does the size and quality of the pre-trained model affect the impact of RLHF?
Zou and his colleagues note that for some tasks GPT-3.5 improved whereas GPT-4 deteriorated.
How do we systematically monitor all these models for longitudinal drift?
What kinds of tasks should be monitored? Is there an information theoretic basis for picking a robust subset of tasks to monitor?
Can the RLHF impact on LLM performance be predicted by computational inspection of the reward model?
Can that inspection be performed without understanding the details of the pre-trained model?
Will we require artificial neurodevelopmental psychologists to avoid crippling the LLMs?
Can Susan Calvin (of Asimov robot story fame) determine the impact of RLHF through linguistic interactions?
Can prompting the developers of RLHF prompts mitigate performance hits?
Is there an engineered path to developing prompts to make RLHF effective without loss of performance?
Should RLHF go through a separate regulatory process than the pre-trained model?
Can RLHF pipelines and content be vetted to be applied to different pre-trained models?
Steering (e.g. through RLHF) can be a much more explicit way of inserting a set of societal or personal values into LLM’s than choosing the data that is used to trained the pre-trained model. For this reason alone, research on the properties of this process is not only of interest to policy makers and ethicists but also to all of us who are working towards the safe deployment of these computational extenders of human competence.
I wrote this post right after reading the paper by Chen, Zaharia and Zou so I know that it’s going to take a little while longer for me to think through what are its broadest implications. I am therefore very interested in hearing your take on what might be good research questions in this space. Also if you have suggestions or corrections to make about this post, please feel free to email me. – July 19th, 2023
The recent publication “Health system-scale language models as all-purpose prediction engines” by Jiang et al. in Nature (June 7th, 2023) piqued my interest. The authors executed an impressive feat by developing a Large Language Model (LLM) that was fine-tuned using data from multiple hospitals within their healthcare system. The LLM’s predictive accuracy was noteworthy, yet it also highlighted the critical limitations of machine learning approaches for prediction tasks using electronic health records (EHRs).
Take a look at the above diagram from our 2021 publication Machine learning for patient risk stratification: standing on, or looking over, the shoulders of clinicians?. It makes the point that the EHR is not merely a repository of objective measurements, but it also includes a record (whether explicit or not) of physician beliefs about the patient’s physiological state and prognosis for every clinical decision recorded. To draw a comparison, using clinicians’ decisions to diagnose and predict outcomes resembles a diligent, well-read medical student who’s yet to master reliable diagnosis. Just as such a student would glean insight from the actions of their supervising physician (ordering a CT scan or ECG, for instance), these models also learn from clinicians’ decisions. Nonetheless, if they were to be left to their own devices, they would be at sea without the cue of the expert decision-maker. In our study we showed that relying solely on physician decisions—as represented by charge details—to construct a predictive model resulted in performances remarkably similar to those models using comprehensive EHR data..
The LLMs from Jiang et al.’s study resemble the aforementioned diligent but inexperienced medical student. For instance, they used the discharge summary to predict readmission within 30 days in a prospective study. These summaries outline the patients’ clinical course, treatments undertaken, and occasionally, risk assessments from the discharging physician. The high accuracy of the LLMs—particularly when contrasted with baselines like APACHE2, which primarily rely on physiological measurements—reveals that the effective use of the clinicians’ medical judgments is the key to their performance.
This finding raises the question: what are the implications for EHR-tuned LLMs beyond the proposed study? It suggests that quality assessment and improvement teams, as well as administrators, should consider employing LLMs as a tool for gauging their healthcare systems’ performance. However, if new clinicians—whose documented decisions might not be as high-quality—are introduced, or if the LLM is transferred to a different healthcare system with other clinicians, the predictive accuracy may suffer. That is because clinician performance is highly variable over time and location. This variability (aka data set shift) might explain the fluctuations in predictive accuracy the authors observed during different months of the year.
Jiang et al.’s study illustrates that LLMs can leverage clinician behavior and patient findings—as documented in EHRs—to predict a defined set of near-term future patient trajectories. This observation paradoxically implies that in the near future, one of the most critical factors for improving AI in clinical settings is ensuring our clinicians are well-trained and thoroughly understand the patients under their care. Additionally, they must be consistent in communicating their decisions and insights. Only under these conditions will LLMs obtain the per-patient clinical context necessary to replicate the promising results of this study more broadly.