I am often asked by (medical or masters) students how to get up to speed rapidly to understand what many of us have been raging and rallying about since the introduction of GPT-4. The challenge is twofold: First the technical sophistication of the students is highly variable. Not all of them have computer science backgrounds. Second, the discipline is moving so fast that not only are there new techniques developed every week but we also are looking back and reconceptualizing what happened. Regardless, what many students are looking for are videos. There are other ways to keep up and I’ll provide those below. If you have other suggestions, leave them in comments section with a rationale.
Video Title
Audience
Comment
URL
[1hr Talk] Intro to Large Language Models
AI or CS expertise not required
1 hour long. Excellent introduction.
https://www.youtube.com/watch?v=zjkBMFhNj_g
Generative AI for Everyone
CS background not required.
Relaxed, low pressure introduction to generative AI. Free to audit. $49 if you want grading.
Good introduction to Transformers and word embeddings and attention vectors along the way.
https://www.youtube.com/watch?v=TQQlZhbC5ps
Illustrated Guide to Transformer Neural Network
If you like visual step by step examples this is for you. Requires CS background
Attention and transformers
https://www.youtube.com/watch?v=4Bdc55j80l8
Practical AI for Instructors and Students
Students or instructors who want to use AI for education.
How to accelerate and customize education using Large Language Models
https://www.youtube.com/watch?v=t9gmyvf7JYo
Recommended Videos
X (Twitter) handles to follow for state-of-the-art AI perspectives without the polemic: @karpathy, @SebastienBubeck, @jeremyphoward, @emollick, @DrJimFan. There are many other useful accounts but these have high signal/noise.
AI in Medicine
Medicine is only one of hundreds of disciplines that are now trying to figure out how to use AI to improve their work while addressing risks. Yet medicine has millions of practitioners worldwide, account for 1/6 of the GDP in the USA, and is relevant to all of us. That does mean that educational resources are exploding but I’ll only include a sprinkle of these below from an admittedly biased and opinionated perspective. (Note to self: include the AI greats from 1950’s onwards in the next version.)
This is a pre-2022 perspective on AI and machine learning with colleagues from Google. Machine Learning in Medicine. And here was a perspective with Andy Beam where we addressed the confusion between machine learning and big data (no, really, that’s why we wrote it.).
A journal I am very happy to be part of : NEJM AI.
Version History
0.1: Basics of generative models and sprinkling of AI in medicine. Very present focused. Next time: AI greats from earlier AI summers and key AI in medicine papers.
Version 0.6 (Revision history at the bottom) November, 30, 2023
Much has been written about harmonizing AI with our ethical standards, a topic of great significance that still demands further exploration. Yet, an even more urgent matter looms: realigning our healthcare systems to better serve patients and society as a whole. We must confront a hard truth: the alignment of these systems with our needs has always been imperfect, and the situation is deteriorating.
My purpose is not to sway healthcare policy but to shed light on this issue for a specific audience: my peers in computer science, along with students in both medicine and computer science. They frequently pose questions to me, prompting this examination. These inquiries aren’t just academic or mercantile; they reflect a deep concern about how our healthcare systems are failing to meet their most fundamental objectives and an intense desire to bring their own expertise, energy and optimism to address these failures.
A sampling of these questions
Which applications to clinical medicine are ripe for improvement or disruption by the application of AI?
What do I have to demonstrate to get my AI program adopted?
Who decides which programs are approved or paid for?
This program we’ve developed helps patients. So why are doctors, nurses and other healthcare personnel so reluctant to use our program?
Why can’t I just market this program directly to patients?
To avoid immediately disappointing any reader, beware, I am not going to answer those questions here although I have done so in the past and will continue to do so. Here I will focus only on the misalignment between organized/establishment healthcare and its mission to improve the health of members of our society. Understanding the misalignment is a necessary preamble to answering the questions of the sort listed above.
Basic Facts of Misalignment of Healthcare
Let’s proceed to some of the basic facts about the healthcare system and the growing misalignments. Again, many of these pertain to several developed countries but they are most applicable to the US.
Primary care is the where you go for preventive care (e.g. yearly checkups) and go first when you have a medical problem. In the US, primary care doctors are amongst the lowest paid. They also have a constantly increasing administrative burden. As a result, despite the growing needs for primary care with the graying of our citizens, the gap between the number of primacy care doctors and the need for such doctors may exceed 40,000 within the next 10 years in the US alone.
Projected shortage in primary care physicians (AAMC study)
In response to the growing gap between the demand for primary care and the availability of primary care doctors, the U.S. healthcare system has seen a notable increase in the employment of nurse practitioners (NPs) and physician assistants (PAs). These professionals now constitute an estimated 25% of the primary care workforce in the United States, a figure that is expected to rise in the coming years.
You might think that the fact that U.S. doctors earn roughly double the income of doctors in Europe would result in a stable workload. Despite this higher pay, they face relentless pressure, often exerted by department heads or hospital administrators, to see more patients each day.
The thorough processes that were once the hallmark of medical training—careful patient history taking, physical examinations, crafting thoughtful diagnostic or management plans, and consulting with colleagues—are now often condensed into forms that barely resemble their original intent. This transformation of medical practice into a high-pressure, high-volume environment contributes to several profound issues: clinician burnout, patient dissatisfaction, and an increased likelihood of clinical errors. These issues highlight a growing disconnect between the healthcare system’s operational demands and the foundational principles of medical practice. This misalignment not only affects healthcare professionals but also has significant implications for patient care and safety.
The acute workforce shortage in healthcare extends well beyond the realm of primary care, touching various subspecialties that are often less lucrative and, perhaps as a result, perceived as less prestigious. Fields such as Developmental Medicine, where children are assessed for conditions like ADHD and autism, pediatric infectious disease, pediatric endocrinology, and geriatrics, consistently face the challenge of unfilled positions year after year.
This shortage is compounded by a growing trend among medical professionals seeking careers outside of clinical practice. Recent surveys indicate that about one-quarter of U.S. doctors are exploring non-clinical career paths in areas such as industry, writing, or education. Similarly, in the UK, half of the junior doctors are considering alternatives to clinical work. This shift away from patient-facing roles points to deeper issues within the healthcare system, including job dissatisfaction, the allure of less stressful or more financially rewarding careers, and perhaps a disillusionment with the current state of medical practice. This trend not only reflects the personal choices of healthcare professionals but also underscores a systemic issue that could further exacerbate the existing shortages in crucial medical specialties, ultimately impacting patient care and the overall effectiveness of the healthcare system.
Doctors have been burned by information technology: Electronic health records (EHRs). Initially introduced as a tool to enhance healthcare delivery, EHRs have increasingly been utilized primarily for documenting care for reimbursement purposes. This shift in focus has led to a significant disconnect between the potential of these systems and their actual use in clinical settings. Most of the currently widely used implementations over the last 15 years have rococo user interfaces that would offend the sensibilities of most “less is more” advocates. Many technologists will be unaware of the details of clinicians’ experience with these systems because EHR companies will have contractually imposed gag orders to prevent doctors from publishing screenshots. Yet these same EHR systems are widely understood to be major contributors to doctor burnout and general disaffection with clinical care. These same EHR’s cost millions (hundreds of millions for a large hospital) and have made many overtaxed hospital information technology leaders wary of adopting new technologies.
At least 25% of the US healthcare costs are administrative. This administrative overhead heaped atop of the provisioning of healthcare services includes the tug of war between healthcare providers and healthcare payors on how much to bill and how much to reimburse. It also includes the authorization for procedures, referrals, the multiple emails and calls to coordinate care between the members of the care team writ large (pharmacist, visiting nurse, rehabilitation hospital, social worker) and the multiple pieces of documentation entailed by each patient encounter (e.g. post-visit note to the patient, to the billing department, to a referring doctor). These non-clinical tasks don’t have the same liability as patient care and the infrastructure to execute them is more mature. As noted by David Cutler and colleagues, this makes it very likely that administrative processes will present the greatest initial opportunity for a broad foothold of AI into the processes of healthcare.
Even in centralized, nationalized healthcare systems there is a natural pressure to do something when faced with a patient who is suffering or worried. Watchful waiting, when medically prudent, requires ensuring that the patient understands that not doing anything might be the best course of action. This requires the doctor to establish trust during the first visit and in future visits, so the patient can be confident that their doctor will be vigilant and ready to change course when needed. This requires a lot more time and communication than many simple treatments or procedures. The pressure to treat is even more acute when reimbursement for healthcare is under a fee-for-service system, as is the case for at least 1/3 of US healthcare. That is, doctors get paid for delivering treatments rather than better outcome. One implication is that advice (by humans or AI) to not deliver a treatment might be in financial conflict with the interests of the clinician.
The substrate for medical decision-making is high-quality data about the patients in our care. Those data are often obtained at considerable effort, cost and risk to the patient (e.g, when involving a diagnostic procedure). Sharing those data across healthcare wherever it is provided has been an obvious and long-sought goal. Yet in many countries, patient data remains locked in propriety systems or accessible to only a few designees. Systematic and continual movement of patient data to follow them across countries is relatively rare and incomplete. EHR companies that have large marketshare therefore have outsized leverage in influencing the process of healthcare, of guiding medical leaders to market patient data (e.g for market research or training AI models). They are often also aligned with healthcare systems that would rather not share clinical data with their competitors. Fortunately, the 21st Century Cures act passed by the US congress has explicitly provided for the support of APIs such as SMART-on-FHIR to allow patients to transport their data to other systems. The infrastructure to support this transport is still in its infancy but has been accelerated by companies such as Apple which have provided customers access to their own healthcare records across hundreds of hospitals.
Finally, at the time of this writing (2023) hospitals and healthcare systems are under enormous pressure to deliver care in a more timely and safer fashion and simultaneously are financially fragile. This double jeopardy was accentuated by the consequences of the 2020 pandemic. It may also be that the pandemic merely accelerated the ongoing misalignment between medical capabilities, professional rewards, societal healthcare needs and an increasingly anachronistic and inefficient medical education and training process. The stresses caused by the misalignment may create cracks into which new models of healthcare may find a growing niche but it might also bolster powerful reactionary forces to preserve the status quo.
Did I miss an important gap relevant to AI/CS scientists, developers or entrepreneurs? Let me know by posting in this post’s comments section (which I moderate) or just reply to my X/Twitter post @zakkohane.
Version
Comment
0.1
Initially covered many more woes of medicine
0.2
Refocused on bits most relevant to AI developers/computer scientists.
0.3
Removed many details that detracted from the message
0.4
Inserted the kinds of questions that I have answered in the past but need to first provide this bulletized version of the misalignments of the healthcare system as a necessary preamble.
0.5
Added more content on EHR’s and corrected cut and paste errors! (Sorry!)
0.6
Added positions unfilled as per https://twitter.com/jbcarmody/status/1729933555810132429/photo/1
In population genetics, it’s canon that selecting for a trait other than fitness will increase the likelihood of disease, or at least characteristics that would decrease survival in the “wild”. This is evident in agriculture, where delicious fat corn kernels are embedded in husks so that human assistance is required for reproduction or where breast-heavy chickens have been bred that can barely walk . I’ve been wondering about the nature of the analogous tradeoff in AI. In my experience with large language models (LLM)—specifically GPT-4—in the last 8 months, the behavior of the LLM has changed over the short interval of my experience. Compared to logged prompt/responses I have from November 2022 (some of which appear in a book) the LLM is less argumentative, more obsequious but also less insightful and less creative. This publication now provides plausible, quantified evidence that there has indeed been a loss of performance in only a few months in GPT-3.5 and GPT-4. This in tasks ranging from mathematical reasoning to sociopolitically enmeshed assessments.
This study by Zou and colleagues at Berkeley and Stanford merits its own post for all its implications for how we assess, regulate, and monitor AI applications. But here, I want to briefly pose just one question that I suspect will be at the center of a hyper-fertile domain for AI research in the coming few years: Why did the performance of these LLMs change so much? There may be some relatively pedestrian reasons: The pre-trained models were simplified/downscaled to reduce response time and electricity consumption or other corner-cutting optimizations. Even if that is the case, at the same time, we know because they’ve said so (see quote below), that they’ve continued to “steer” (“alignment” seems to be falling into disfavor) the models using a variety of techniques and they are getting considerable leverage from doing so.
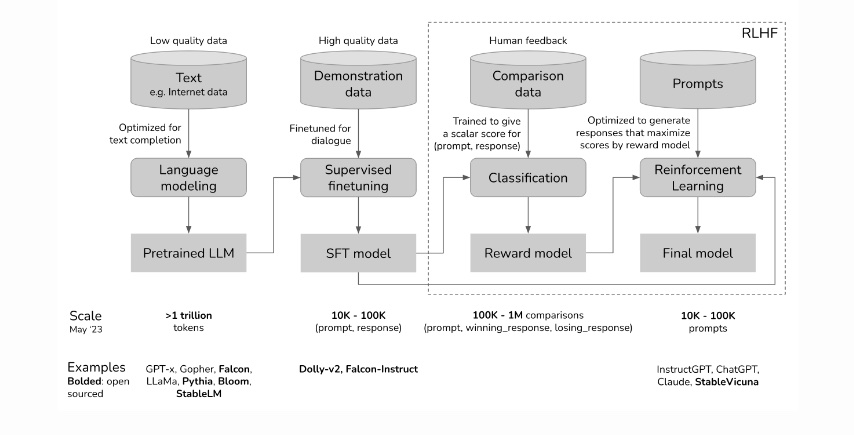
Much of this steering is driven by human-sourced generation and rating of prompts/responses to generate a model that is then interposed between human users and the pre-trained model (see this post by Chip Huyen from which I copied the first figure above which outlines how RLHF—Reinforcement Learning from Human Feedback—is implemented to steer LLMs). Without this steering, GPT would often generate syntactically correct sentences that would be of little interest to human beings. So job #1 of RLHF has been to generate human relevant discourse. The success of ChatGPT suggests that RLHF was narrowly effective in that sense. Early unexpected antisocial behavior of GPT gave further impetus to additional steering imposed through RLHF and other mechanisms.
The connections between the pre-trained model and the RLHF models are extensive. It is therefore possible that modifying the output of the LLM through RLHF can have consequences beyond the narrow set of cases considered during the ongoing steering phase of development. That possibility raises exciting research questions, a few of which I have listed below.
Question
Elaboration and downstream experiments
Does RLHF degrade LLM performance?
What kind of RLHF under what conditions? When does it improve performance?
How does the size and quality of the pre-trained model affect the impact of RLHF?
Zou and his colleagues note that for some tasks GPT-3.5 improved whereas GPT-4 deteriorated.
How do we systematically monitor all these models for longitudinal drift?
What kinds of tasks should be monitored? Is there an information theoretic basis for picking a robust subset of tasks to monitor?
Can the RLHF impact on LLM performance be predicted by computational inspection of the reward model?
Can that inspection be performed without understanding the details of the pre-trained model?
Will we require artificial neurodevelopmental psychologists to avoid crippling the LLMs?
Can Susan Calvin (of Asimov robot story fame) determine the impact of RLHF through linguistic interactions?
Can prompting the developers of RLHF prompts mitigate performance hits?
Is there an engineered path to developing prompts to make RLHF effective without loss of performance?
Should RLHF go through a separate regulatory process than the pre-trained model?
Can RLHF pipelines and content be vetted to be applied to different pre-trained models?
Steering (e.g. through RLHF) can be a much more explicit way of inserting a set of societal or personal values into LLM’s than choosing the data that is used to trained the pre-trained model. For this reason alone, research on the properties of this process is not only of interest to policy makers and ethicists but also to all of us who are working towards the safe deployment of these computational extenders of human competence.
I wrote this post right after reading the paper by Chen, Zaharia and Zou so I know that it’s going to take a little while longer for me to think through what are its broadest implications. I am therefore very interested in hearing your take on what might be good research questions in this space. Also if you have suggestions or corrections to make about this post, please feel free to email me. – July 19th, 2023
The recent publication “Health system-scale language models as all-purpose prediction engines” by Jiang et al. in Nature (June 7th, 2023) piqued my interest. The authors executed an impressive feat by developing a Large Language Model (LLM) that was fine-tuned using data from multiple hospitals within their healthcare system. The LLM’s predictive accuracy was noteworthy, yet it also highlighted the critical limitations of machine learning approaches for prediction tasks using electronic health records (EHRs).
Take a look at the above diagram from our 2021 publication Machine learning for patient risk stratification: standing on, or looking over, the shoulders of clinicians?. It makes the point that the EHR is not merely a repository of objective measurements, but it also includes a record (whether explicit or not) of physician beliefs about the patient’s physiological state and prognosis for every clinical decision recorded. To draw a comparison, using clinicians’ decisions to diagnose and predict outcomes resembles a diligent, well-read medical student who’s yet to master reliable diagnosis. Just as such a student would glean insight from the actions of their supervising physician (ordering a CT scan or ECG, for instance), these models also learn from clinicians’ decisions. Nonetheless, if they were to be left to their own devices, they would be at sea without the cue of the expert decision-maker. In our study we showed that relying solely on physician decisions—as represented by charge details—to construct a predictive model resulted in performances remarkably similar to those models using comprehensive EHR data..
The LLMs from Jiang et al.’s study resemble the aforementioned diligent but inexperienced medical student. For instance, they used the discharge summary to predict readmission within 30 days in a prospective study. These summaries outline the patients’ clinical course, treatments undertaken, and occasionally, risk assessments from the discharging physician. The high accuracy of the LLMs—particularly when contrasted with baselines like APACHE2, which primarily rely on physiological measurements—reveals that the effective use of the clinicians’ medical judgments is the key to their performance.
This finding raises the question: what are the implications for EHR-tuned LLMs beyond the proposed study? It suggests that quality assessment and improvement teams, as well as administrators, should consider employing LLMs as a tool for gauging their healthcare systems’ performance. However, if new clinicians—whose documented decisions might not be as high-quality—are introduced, or if the LLM is transferred to a different healthcare system with other clinicians, the predictive accuracy may suffer. That is because clinician performance is highly variable over time and location. This variability (aka data set shift) might explain the fluctuations in predictive accuracy the authors observed during different months of the year.
Jiang et al.’s study illustrates that LLMs can leverage clinician behavior and patient findings—as documented in EHRs—to predict a defined set of near-term future patient trajectories. This observation paradoxically implies that in the near future, one of the most critical factors for improving AI in clinical settings is ensuring our clinicians are well-trained and thoroughly understand the patients under their care. Additionally, they must be consistent in communicating their decisions and insights. Only under these conditions will LLMs obtain the per-patient clinical context necessary to replicate the promising results of this study more broadly.
In a world awash with the rapid tide of generative AI technologies, governments are waking up to the need for a guiding hand. President Biden’s Executive Order is an exemplar of the call to action, not just within the halls of government but also for the sprawling campuses of tech enterprises. It’s a call to gather the thinkers and doers and set a course that navigates through the potential perils and benefits these technologies wield. This is more than just a precaution; it’s a preemptive measure. Yet these legislative forays are more like sketches than blueprints, in a landscape that’s shifting, and the reticence of legislators is understandable and considered. After all, they’re charting a world where the very essence of our existence — our life, our freedom, our joy — could be reshaped by the tools we create.
On a brisk autumn day, the quiet serenity of Maine became the backdrop for a gathering: The RAISE Symposium, held on October 30th, which drew some 60 souls from across five continents. Their mission? To venture beyond the national conversations and the burgeoning frameworks of regulation that are just beginning to take shape. We convened to ponder the questions of generative AI — not in the abstract, but as they apply to the intimate dance between patient and physician. The participants aimed to cast a light on the issues that need to be part of the global dialogue, the ones that matter when care is given and received. We did not an attempt to map the entirety of this complex terrain, but to mark the trails that seemed most urgent.
The RAISE Symposium’s attendees raised (sorry) a handful of issues and some potential next steps that appeared today in the pages of NEJM AI and Nature Medicine. Here I’ll focus on a singular quandary that seems to hover in the consultation rooms of the future: For whom does the AI’s medical counsel truly toll? We walk into a doctor’s office with a trust, almost sacred, that the guidance we receive is crafted for our benefit — the patient, not the myriad of other players in the healthcare drama. It’s a trust born from a deeply-rooted social contract on healthcare’s purpose. Yet, when this trust is breached, disillusionment follows. Now, as we stand on the precipice of an era where language models offer health advice, we must ask: Who stands to gain from the advice? Is it the patient, or is it the orchestra of interests behind the AI — the marketers, the designers, the stakeholders whose fingers might so subtly weigh on the scale? The symposium buzzed with talk of aligning AI, but the compass point of its benefit — who does it truly point to? How do we ensure that the needle stays true to the north of patient welfare? Read the article for some suggestions from RAISE participants.
As the RAISE Symposium’s discussions wove through the thicket of medical ethics in the age of AI, other questions were explored. What is the role of AI agents in the patient-clinician relationship—do they join the privileged circle of doctor and patient as new, independent arbiters? Who oversees the guardianship of patient data, the lifeblood of these models: Who decides which fragments of a patient’s narrative feed the data-hungry algorithms?
The debate ventured into the autonomy of patients wielding AI tools, probing whether these digital oracles could be entrusted to patients without the watchful eye of a human professional. And finally, we contemplated the economics of AI in healthcare: Who writes the checks that sustain the beating heart of these models, and how might the flow of capital sculpt the very anatomy of care? The paths chosen now may well define the contours of healthcare’s landscape for generations to come.
After you have read the jointly written article, I and the other RAISE attendees hope that it will spark discourse between you and your colleagues. There is an urgency in this call to dialogue. If we linger in complacency, if we cede the floor to those with the most to gain at the expense of the patient, we risk finding ourselves in a future where the rules are set, the die is cast, and the patient’s voice is but an echo in a chamber already sealed. It is a future we can—and must—shape with our voices now, before the silence falls.
I could have kicked off this blog post with a pivotal query: Should we open the doors to AI in the realm of healthcare decisions, both for practitioners and the people they serve? However considering “no” as an answer seemed disingenuous. Why should we not then question the very foundations of our digital queries—why, after all, do we permit the likes of Google and Bing to guide us through the medical maze? Today’s search engines, with their less sophisticated algorithms, sit squarely under the sway of ad revenues, often blind to the user’s literacy. Yet, they remain unchallenged gateways to medical insights that sway critical health choices. Given that outright denial of search engines’ role in health decision-making seems off the table and acknowledging that generative AI is already a tool in the medical kit for both doctors and their patients, the original question shifts from a hypothetical to a pragmatic sphere. The RAISE Symposium stands not alone but as one voice among many, calling for open discussions on how generative AI can be safely and effectively incorporated into healthcare.
And just for a moment he forgot, or didn’t want to remember, that other robots might be more ignorant than human beings. His very superiority caught him.
Dr. Susan Calvin in “Little Lost Robot” by Isaac Asimov, first published in Astounding Science Fiction, 1947 and anthologized by Isaac Asimov in I, Robot, Gnome Press, 1950.
Version 0.1 (Revision history at the bottom) December 28th, 2023
When I was a doctoral student working on my thesis in computer science in an earlier heyday of artificial intelligence, if you’d ask me how I how I’d find out why a program did not perform as expected, I would come up with a half dozen heuristics, most of them near cousins of standard computer programming debugging techniques.1 Even though I was a diehard science fiction reader, I gave short shrift to the techniques illustrated by the expert robopsychologist—Dr. Susan Calvin—introduced into his robot short stories in the 1940’s by Isaac Asimov. These seemed more akin the the logical dissections performed by Conan Doyle’s Sherlock Holmes than anything I could recognize as computer science.
Yet over the last five years, particularly since 2020, English (and other language) prompts—human-like statements or questions, often called “hard prompts” to distinguish them from “soft prompts”2 —have come into wide use. Interest in hard prompts grew rapidly after the release of ChatGPT and was driven by creative individuals who figured out, through experimentation, which prompts worked particularly well for specific tasks. This was jarring to many computer scientists such as Andrej Karpathy who declared “The hottest new programming language is English.” Ethan and Lilach Mollick are exemplars of non-computer scientist creatives that have pushed the envelope in their own domain using mastery of hard prompts. They have been inspired leaders in developing sets of prompts for many common educational tasks that resulted in functionality that has surpassed and replaced whole suites of commercial educational software.
After the initial culture shock, many researchers have started working on ways to automate optimization of hard prompts (e.g. Wen et al., Sordoniet al.) How well this works for all applications of generative AI (now less frequently referred to as large language models, and foundation models, even though technically they do not denote the same thing) in medicine in particular remains to be determined. I’ll try to write a post about optimizing prompts for medicine soon, but right now, I cannot help but notice that in my interactions with GPT-4 or Bard, when I do not get the answer I expect, my interactions resemble a conversation with a sometimes reluctant, sometimes confused, sometimes ignorant assistant who has frequent flashes of brilliance.
Early on, some of the skepticism about the performance of large language models centered on the capacity of these models for “theory of mind” reasoning. Understanding the possible state of mind of a human was seen as an important measure of artificial general intelligence. I’ll step away from the debate of whether or not GPT-4, Bard et al, show evidence of theory of mind but instead posit that having of theory of the “mind3” of the generative AI program gives humans better results when using such a program.
What does it mean to have a theory of the mind of the generative AI? I am most effective in using a generative AI program when I have a set of expectations of how it will respond to a prompt based on both my experience with that program over many sessions and its responses so far in this specific session. That is, what did they “understand” from my last prompt and what might that understanding be as informed by my experience with that program? Sometimes, I check on the validity of my theory of their mind by asking an open ended question. This leads to a conversation which is much closer to the work of Dr. Susan Calvin than to that of a programmer. Although the robots had complex positronic brains, Dr. Calvin did not debug the robots by examining their nanoscale circuitry. Instead she conducted logical and very rarely emotional conversations in English with the robots. The low level implementation layer of robot intelligence were NOT where her interventions were targeted. That is why her job title was robopsychologist and not computer scientist. A great science fiction story does not serve as technical evidence or a scientific proof but thus far it has served as a useful collection of metaphors for our collective experience working with generative AI using these Theory of AI-Mind (?TAIM) approaches.
In future versions of this post, I’ll touch on the pragmatics of Theory of AI-Mind for effective use of these programs but also on the implications for “alignment” procedures.
Version
0.1
Initial presentation of theory mind of humans vs programming generative AI with a theory of mind of the AI.
Version History
Some techniques were more inspired by the 1980’s AI community’s toolit including dependency directed backtracking and Truth Maintenance Systems. ↩︎
Soft prompts are frequently implemented as embeddings, vectors representing the relationship between tokens/words/entities across a training corpus. ↩︎
I’ll defer the fun but tangential discussion of what mind means in this cybernetic version of the mind-body problem. Go read I Am A Strange Loop if you dare, if you want to get ahead of the conversation. ↩︎
6 Topics contained in tweets about COVID-19 in 2020
My daughter has pointed out to me that I spend too much time on Twitter and to emphasize the point she bought me a Twitter addict mug. She urged me to keep to science and big ideas rather than science gossip. Rather than argue that she is unfairly characterizing the way I keep up with developments in the world of science and medicine, I decided that the best defense would be to turn to analyzing tweets and make my Twitter habit a programming project. As my timeline was filled up with tweets about COVID-19, I’ve decided to focus on tweets about the disease and virus. This has afforded me the opportunity to brush up on the Tidyverse and start to sharpen my data science tools for this remarkable, surely biased and yet highly informative stream of messages from around the world about this pandemic, now rounding out its 1st year. This is only part 1. I left the other parts on the cutting floor so that I could quickly check to see if my prior expectations about content were correct (spoiler: there were not).
This hyperlink will bring you to an HTML file with the first version of the Part 1 analysis. I’ll be providing additional versions as I find time to steal from research, teaching and research supervision. Suggestions on presentation or analyses are much appreciated. Comments and critique are welcome too.
Imagine a spectacularly accurate machine learning (ML) algorithm for medicine. One that has been grown and fed with the finest of high quality clinical data, culled and collated from the most storied and diverse clinical sites across the country. It can make diagnoses and prognoses even Dr. House would miss.
Then the covid19 pandemic happens. All of a sudden, prognostic accuracy collapses. What starts as a cough ends up as Acute Respiratory Distress Syndrome (ARDS) at rates not seen in the last decade of training data. The treatments that worked best for ARDS with influenza don’t work nearly as well. Medications such as dexamethasone that have been shown not to help patients with ARDS prove remarkably effective. Patients suffer and the ML algorithm appears unhelpful. Perhaps this is overly harsh. After all, this is not just a different context from the original training data (i..e “dataset shift”), it’s a different causal mechanism of disease. Also, unlike some emergent diseases which present with unusual constellations of findings—like AIDS—coivd19 looks like a lot of common inconsequential infections often until the patient is sick enough to be admitted to a hospital. Furthermore, human clinicians were hardly doing better in March of 2020. Does that mean that if we use ML in the clinic, then clinicians cannot decrease alertness for anomalous patient trajectories? Such anomalies are not uncommon but rather a property of the way medical care changes all the time. New medications are introduced every year with novel mechanisms of action which introduce new outcomes which can be discontinuous as compared to prior therapies and also novel associations of adverse events. Similarly new devices create new biophysical clinical trajectories with new feature sets.
These challenges are not foreign to the current ML literature. There are scores of frameworks for anomaly detection1, for model switching 2, for feature evolvable streaming learning3. They are also not new to the AI literature. Many of these problems were encountered in symbolic AI and were closely related to the Frame Problem that bedeviled AI researchers in the 1970s and 1980s. I’ve pointed this out with my colleague Kun-Hsing Yu4 and discussed some of the urgent measures we must take to ensure patient safety. Many of these are obvious such as clinician review of cases with atypical features of feature distributions, calibration with human feedback and repeated prospective trials. These stopgap measures do not however address the underlying brittleness that will and should decrease trust in the performance of AI programs in clinical care. So although these challenges are not foreign , there is an exciting and urgent opportunity for researchers in ML to address them in the clinical context especially because there is a severe data penury relative to our other ML application domains. I look forward to discussions on these issues in our future ML+clinical meetings (including our SAIL gathering).
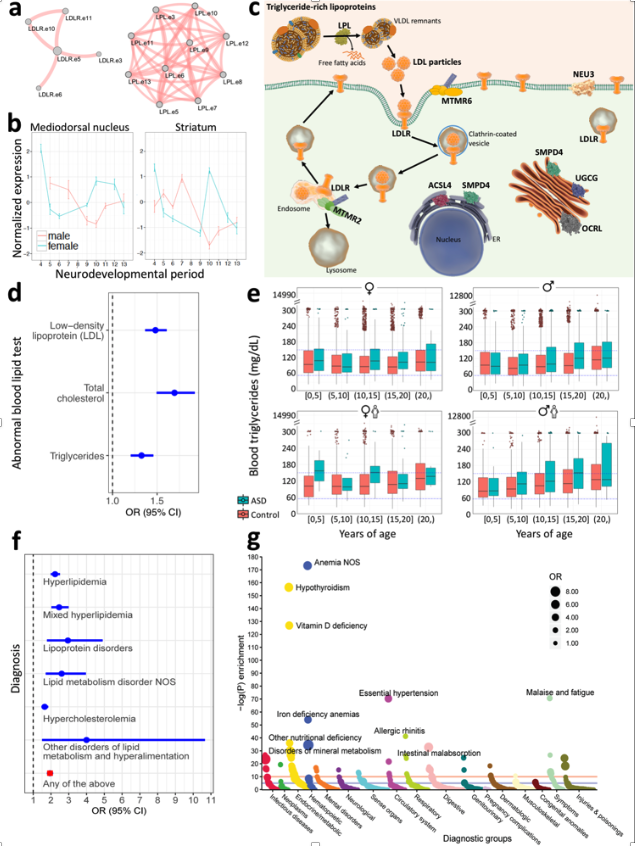
I may get into the details below, but this recent publication in Nature Medicine gives me an opportunity to revisit the problematic validity and utility of the autism diagnosis. We took a clinical insight and used it to focus on genes that had dramatically different expression patterns during the critical period of brain development. We then whittled down that collection of genes to those that bore mutations/rare variants that were found through exome sequencing in patients with autism but not those (e.g. relatives) without autism. We found four functional groups of genes that were enriched in affected individual. One of these groups—lipid metabolism—has been given short shrift, if any, in previous genetic studies. A comprehensive review of mouse models in the Jackson Laboratory revealed that many mice with a “knockout” mutation in one of the lipid metabolism genes had behavioral characteristics very similar to classical mouse models of autism. But that’s mice. We also studied tens of thousands of individual humans with autism through their electronic health record or through their claims data. Even after correcting for treatments that might affect lipid metabolism we found a substantial increased prevalence of dyslipidemia in patients with autism relative to controls. Compared to unaffected siblings, the odds ratio was approximately 1.5 (150%). More studies, as usual, will be required to confirm this dyslipidemia-autism hypothesis but the question is raised should these individuals with dyslipidemia have the same diagnosis as those patients with autism and with, for example, a immune signalling disorder?
Figure: Convergence of Autism-segregating deleterious genetic varants on lipid regulation functions, clinically reflected by an association between altered lipid profiles and autism, as well as enrichment of dyslipidemia diagnoses in individuals with autism (see publication for full description).
As late as the 18th century, a diagnosis of dropsy was a diagnosis that reputable clinicians could make without embarrassment. This diagnosis of the abnormal accumulation of fluid only gave way to diagnoses of heart failure, liver failure or kidney failure causing fluid accumulation in the 19th century. By the end of the 20th century making a diagnosis of heart failure without distinguishing whether it was due to valvular disease, ischemic heart disease, genetically inherited myopathy or another dozen causes would raise eyebrows. Not only because it would be ignorant but because these different causes have differing natural histories and most importantly, differing optimal treatments. In that perspective the diagnosis of heart failure only informs us of a shared set of findings (e.g. symptoms, clinical measurements) which do not distinguish between the various causes nor provides and disease-specific guidance for prognosis or treatment. As we reveal mechanistically distinct causes of autism, many but not all genetic, we’ve seen the definition of groups of patients who have little in common other than the DSM criteria for autism. As we’ve shown, autism is clinically manifested in far more diverse ways than would be suggested by DSM. Just by studying electronic health record data we can distinguish subgroups of individuals who, in addition to the DSM definition, have epilepsy, immunological disorders (e.g. inflammatory bowel disease, type 1 diabetes mellitus, infections) or psychiatric disorders.
There is an obvious value to the diagnosis of autism that I’ve omitted. A sociopolitical one. All the diseases that have in common autistic findings collectively have prevalence of over 1%. That puts autism somewhere between the incidence of type 1 diabetes and skin melanoma cancer in Americans, each of which have benefited from appropriate and considerable private and public attention and support. The high collective prevalence of diseases with clinical manifestations of autism, regardless of other findings, has enabled important changes such as school support programs, massively increased research funding over the past two decades and progress in screening programs. At the same time, this lumping of different causes and clinical courses, just as for the example of heart failure, does create confusion among clinicians and researchers. It also causes hurt and acrimony for patients and their families which rapidly acquires political overtones as narrated by this NPR program.
“[in a] conversation between Ari Ne’eman, who is a very, very prominent and successful activist for the concept of neurodiversity. And Ari Ne’eman, whom we have a lot of respect for, has been very, very successful in promulgating the idea that people with autism should be accepted as they are. And he had a conversation with a mother named Liz Bell. Liz Bell is the mother of a young man named Tyler. In his mom’s opinion, Tyler’s experience of autism is very, very limiting in his life and his ability to dress himself, to shave himself, to feed himself, to go out the front door by himself and not run into traffic. And these are two very, very different views of what autism represents that come down to the fact that the spectrum is so broad that there is room for an Ari Ne’eman on it and there is room for a Tyler Bell on it. And the basic disagreement between them is whether autism is something that should be cured — whether the traits that limit Tyler’s ability to be independent in life should be treated to make those traits go away. On one side, Ari is saying that it’s suppressing who he actually is and his identity; on the other side is Tyler’s mother saying that to treat him, and even cure him, of his autism would be to liberate who he is.”
Similarly, in research studies there is a point at which lumping all the different disorders is less helpful than splitting them apart. Just as for heart failure in the 21st century, realizing there are different underlying diseases allows advances in diagnostic accuracy but also in therapeutic efficacy. In the Undiagnosed Disease Network, we’ve shown again and again that more detailed clinical characterizations (aka deep phenotyping) are at least as important as whole genome sequencing in arriving at a diagnosis for these patients on long and difficulty diagnostic journeys. Several of the patients seen in the Undiagnosed Disease Network had findings fully consistent with autism in addition to other findings that led to the investigations that discovered a new disease.
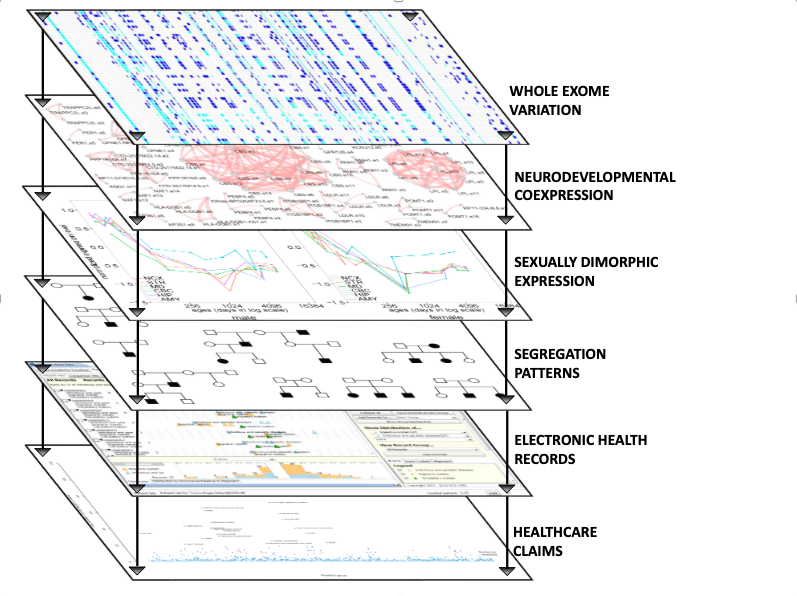
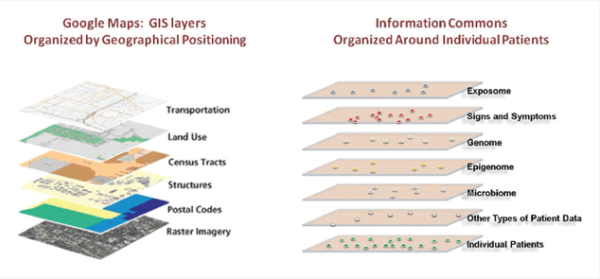
I could easily go on for thousands of words about the challenge and opportunity for modern diagnostic approaches. I’ll forestall the temptation by referring to a National Academy of Sciences report on Precision Medicine that I had the privilege to contribute to. This report was often misunderstood as arguing for molecular, genome scale characterizations of disease. This was only true in part and missed the central contention. Our argument was that by examining groups of patients and finding what they had in common using multiple data modalities (see the figure from the report, below) clinical, environmental monitoring, epigenetic, microbiome, we acquired more relevant, scientifically and clinically, diagnostic perspectives.
This multiaxial perspective of diagnosis influenced the direction of our investigation as intentionally styled in this diagram from the supplementary figures in the publication, below.
These findings of a subgroup of patients with autism who have dyslipidemia are of course just the beginning of a set of follow-on investigations. As in much of science, a useful investigation poses more questions than it answers, How does a disorder of lipid metabolism during neurodevelopment cause pathophysiologies that include findings of autism? Would early detection help treatment? Would normalization of lipid metabolism during neurodevelopment affect the course of disease? Which specific perturbations of lipid metabolism have the largest impact on neurodevelopment? These are questions which could not be posed with an overly rigid and monolithic definition of autism. Now, with the multiaxial approach of precision medicine, many more such questions can be asked and investigated.
At first, I waited for others in the government, industry and in academia to put together the data and the analyses that would allow clinicians to practice medicine that has worked the best: knowing what to expect when treating a patient. With the first COVID19 patients, ignorance was to be expected but with hundreds of patients seen early on in Europe, we could expect solid data about the clinical course of these patients. Knowing what to expect would allow doctors and nurses to be on the look out for different turns in the trajectory of their patients and thereby act rapidly and without having to wait for a full morbid declaration of yet another manifestation of viral infection pathology. Eventually we could learn what works and what does not but first just knowing what to expect would be very helpful. I’m a “cup half-full” optimist but when, in March, I saw that there were dozens of efforts that would yield important results but in months rather than weeks [If there’s interest, I can post an explanation of why I came to that conclusion], I decided that I would try to see if I could do something useful with my colleagues in biomedical informatics. Here I’ll focus on what I have found amazing—that groups can work together on highly technical tasks to complete multi-institutional analyses in less than a handful of weeks if they have shared tools, whether open source or proprietary but most importantly, if they have detailed understanding of the data from their specific home institution.
I first reached out to my i2b2 colleagues with a quick email. What are “i2b2 colleagues”? Over 15 years ago, I helped start a NIH-funded national center for biocomputing predicated on the assumption that by instrumenting the healthcare enterprise we could use the data acquired during the course of healthcare (at considerable financial cost and grueling effort of the healthcare workforce, but that’s another story). One of our software products was a free and open source software system called i2b2 (named after our NIH-funded national center for biomedical computing: Informatics for Integrating Biology and the Bedside) that enable data to be extracted by authorized users from various proprietary electronic health record systems—EHR. i2b2 was adopted by hundreds of academic health centers and an international community of informaticians work together to share knowledge (eg. how to analyze EHR data) was formed. The group meets twice a year, once in the US and once in Europe and has a non-profit foundation to keep it organized. This is the “i2b2” group I sent an email out to. I wrote that there was an opportunity to rapidly contribute to our understanding of the clinical course. We were going to have to focus on the data that was available now, was useful in the aggregate (obtaining permission to share individual patient data across institutions let alone countries is a challenging and lengthy process). As most of us were using the same software to extract data from the health record, we had a head start but we all knew there would be a lot of thought and work required to succeed. Among the many tasks we had to address:
Make sure that the labs reported by each hospital were the same ones. A glucose result can be recorded under dozens of different names in an EHR. Which one(s) should be picked? Which standard vocabulary should be used to name that glucose and other labs (also known as the terrifyingly innocuous-sounding yet soul-deadening process of “data harmonization.”
Determine what constitutes a COVID19 patient? In some hospitals they received patients said to be COVID19 positive but they don’t know positive by which test. In others they use two specific tests. If the first is negative and the second is positive is the time of diagnosis: the admission, the time of the first test or second test?
Assigning these tasks across more than 100 collaborators in 5 countries during the COVID19 mandatory confinement and then coordinating these without a program manager was going to be challenging under any conditions. Doing so with the goal of showing results within weeks, even moreso. In addition to human resourcefulness and passion we were fortunate to have a few tools that made this complex international process a tractable one. These were Slack, Zoom, Google documents, Jupyter notebooks, Github and a shared workspace on the Amazon cloud (where the aggregate data was stored, the individual patient data remained at all the hospital sites). We divided the tasks into subtasks (e.g. common data format, visualization, results website, manuscript writing, data analysis) and created a Slack channel for each. Then those willing to work on the subtask self-organized on each of their respective channels. Three out of the five tools I’ve listed above were not available just 10 years ago.
We were able to publish the first results and a graphically sophisticated website within 4 weeks. See covidclinical.net for the result. That and pre-print. All of this with consumer-level tools and of course a large prior investment in open source software designed for the analysis of electronic health records. Now we have a polished version of the pre-print published in Nature Digital Medicine and a nice editorial.
Nonetheless, the most important takeaway from this rapid and successful sprint to characterize the clinical course of COVID19 is the familiarity each of the informaticians at each clinical site had with their institutional data. This certainly did help them respond rapidly to data requests but that was less important than understanding precisely the semantics of their own data. Even sites that would have the same electronic health record vendor would have practice styles that would mean that a laboratory name (e.g. Troponin) in one clinic would not be the same test as in the ICU laboratory. Sorting that out in multiple Zoom and Slack conversations required dozens of conversations. Yet, many of the commercial aggregation efforts are of necessity blind to these distinctions because their business model precludes this detailed back and forth with each source of clinical data. Academic aggregation efforts tend to be more fastidious about aligning semantics across sites but it’s understandable that the committee-driven processes that result are ponderous and with hundreds of hospitals take months, at least. Among the techniques we used to maintain our agility was a ruthless focus on a subset of the data for a defined set of questions and to steadfastly refuse to expand our scope until we completed the first, narrowly defined tasks, as encapsulated by our first pre-print. Our experience with international colleagues using i2b2 since 2006 also created a lingua franca and patience with reciprocal analytic “favor-asking.” 4CE has continued to have multiple meetings per week and I hope to add to this narrative in the near future.