In population genetics, it’s canon that selecting for a trait other than fitness will increase the likelihood of disease, or at least characteristics that would decrease survival in the “wild”. This is evident in agriculture, where delicious fat corn kernels are embedded in husks so that human assistance is required for reproduction or where breast-heavy chickens have been bred that can barely walk . I’ve been wondering about the nature of the analogous tradeoff in AI. In my experience with large language models (LLM)—specifically GPT-4—in the last 8 months, the behavior of the LLM has changed over the short interval of my experience. Compared to logged prompt/responses I have from November 2022 (some of which appear in a book) the LLM is less argumentative, more obsequious but also less insightful and less creative. This publication now provides plausible, quantified evidence that there has indeed been a loss of performance in only a few months in GPT-3.5 and GPT-4. This in tasks ranging from mathematical reasoning to sociopolitically enmeshed assessments.
This study by Zou and colleagues at Berkeley and Stanford merits its own post for all its implications for how we assess, regulate, and monitor AI applications. But here, I want to briefly pose just one question that I suspect will be at the center of a hyper-fertile domain for AI research in the coming few years: Why did the performance of these LLMs change so much? There may be some relatively pedestrian reasons: The pre-trained models were simplified/downscaled to reduce response time and electricity consumption or other corner-cutting optimizations. Even if that is the case, at the same time, we know because they’ve said so (see quote below), that they’ve continued to “steer” (“alignment” seems to be falling into disfavor) the models using a variety of techniques and they are getting considerable leverage from doing so.
[23:45 Fridman-Altman podcast] “Our degree of alignment increases faster than our rate of capability progress, and I think that will become more and more important over time.”
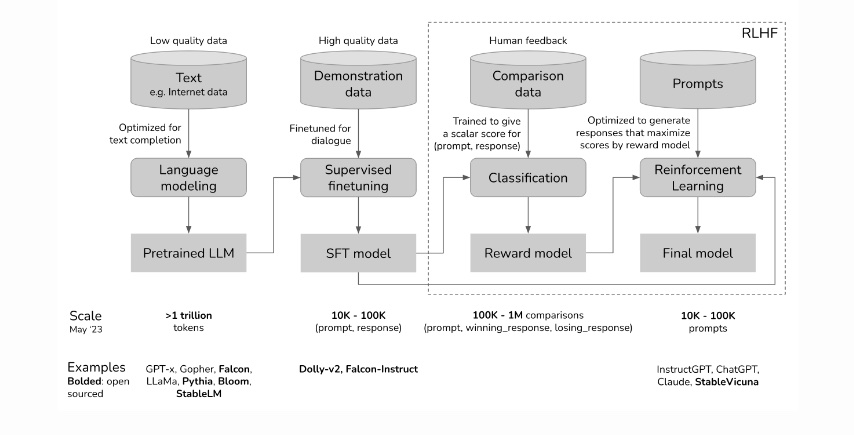
Much of this steering is driven by human-sourced generation and rating of prompts/responses to generate a model that is then interposed between human users and the pre-trained model (see this post by Chip Huyen from which I copied the first figure above which outlines how RLHF—Reinforcement Learning from Human Feedback—is implemented to steer LLMs). Without this steering, GPT would often generate syntactically correct sentences that would be of little interest to human beings. So job #1 of RLHF has been to generate human relevant discourse. The success of ChatGPT suggests that RLHF was narrowly effective in that sense. Early unexpected antisocial behavior of GPT gave further impetus to additional steering imposed through RLHF and other mechanisms.
The connections between the pre-trained model and the RLHF models are extensive. It is therefore possible that modifying the output of the LLM through RLHF can have consequences beyond the narrow set of cases considered during the ongoing steering phase of development. That possibility raises exciting research questions, a few of which I have listed below.
| Question | Elaboration and downstream experiments |
|---|---|
| Does RLHF degrade LLM performance? | What kind of RLHF under what conditions? When does it improve performance? |
| How does the size and quality of the pre-trained model affect the impact of RLHF? | Zou and his colleagues note that for some tasks GPT-3.5 improved whereas GPT-4 deteriorated. |
| How do we systematically monitor all these models for longitudinal drift? | What kinds of tasks should be monitored? Is there an information theoretic basis for picking a robust subset of tasks to monitor? |
| Can the RLHF impact on LLM performance be predicted by computational inspection of the reward model? | Can that inspection be performed without understanding the details of the pre-trained model? |
| Will we require artificial neurodevelopmental psychologists to avoid crippling the LLMs? | Can Susan Calvin (of Asimov robot story fame) determine the impact of RLHF through linguistic interactions? |
| Can prompting the developers of RLHF prompts mitigate performance hits? | Is there an engineered path to developing prompts to make RLHF effective without loss of performance? |
| Should RLHF go through a separate regulatory process than the pre-trained model? | Can RLHF pipelines and content be vetted to be applied to different pre-trained models? |
Steering (e.g. through RLHF) can be a much more explicit way of inserting a set of societal or personal values into LLM’s than choosing the data that is used to trained the pre-trained model. For this reason alone, research on the properties of this process is not only of interest to policy makers and ethicists but also to all of us who are working towards the safe deployment of these computational extenders of human competence.
I wrote this post right after reading the paper by Chen, Zaharia and Zou so I know that it’s going to take a little while longer for me to think through what are its broadest implications. I am therefore very interested in hearing your take on what might be good research questions in this space. Also if you have suggestions or corrections to make about this post, please feel free to email me. – July 19th, 2023